Selasa, 17 Maret 2015
Nama/NIM: I Gede Kusuma Ary Jaya/1204505034
Jurusan/Fakultas/Universitas: Teknologi Informasi/Teknik/Universitas Udayana
Mata Kuliah: Sistem Temu Kembali Informasi
Dosen: I Putu Agus Eka Pratama, S.T., M.T.
Kali ini saya akan membahas salah satu pertanyaan teman pada
mata kuliah Sistem Temu Kembali Informasi. Pertanyaannya adalah bagaimana cara
kerja search engine melakukan proses pencarian sesuai dengan keyword? Saya akan
menjawab sesuai pemahaman dan juga dari referensi yang sudah saya dapatkan.
Saat user mengetikkan keyword di kotak pencarian search
engine misalnya google, maka apa yang user ketikkan itu akan terkirim dan
diproses di sistem search engine. Search engie akan bekerja mencari
petunjuk-petunjuk untuk memahami apa yang user inginkan, dan di sini ada 6
proses, yaitu:
- Ejaan, untuk menilai apakah ejaan anda sudah benar, dan
jika salah maka Google akan memberi saran.
- Autocomplete, di mana Google memperkirakan apa yang
kira-kira dicari dengan berbagai variasi makna lainnya.
- Sinonim, Google berusaha melihat dokumen-dokumen lain yang
mengandung kata-kata yang sinonim dengan pencarian user.
- Metode Pencarian, Google juga menyediakan data lain dalam
format tertentu seperti video, atau gambar yang berkaitan dengan kata kunci
tersebut.
- Google Instant, yang berusaha menampilkan hasil secepat
mungkin kepada user.
Dari semua petunjuk yang dikumpulkan di atas Google akan
menarik data dari tempat penyimpanannya yang disebut index, kemudian data akan
ditampilkan. Proses menampilkan data ini (ranking) harus melalui algoritma
Google, yaitu:
1. Kualitas Situs dan Halaman
Algoritma Google akan bekerja untuk mengenali seberapa
terpercaya, bereputasi, dan berotoritasnya suatu sumber dengan menggunakan
beberapa parameter. Salah satu di antara parameter itu adalah page rank.
2. Kesegaran
Google juga memandang penting untuk mempertimbangkan
informasi-informasi terbaru untuk ditampilkan dalam hasil pencariannya.
3. Pencarian Aman
Google sebisa mungkin mengurangi hasil pencarian yang
berkonten dewasa dari hasil pencarian user (kecuali user memang mencari konten
dewasa). Jadi kalau user bukan mencari situs konten dewasa, tapi memasang iklan
yang menuju situs yang mengandung konten dewasa, maka kemungkinan user untuk
ranking akan berkurang.
4. Konteks Pengguna
Google juga akan melihat posisi geografis kita dan cookie
pada komputer untuk menentukan ranking halaman yang ditampilkannya.
5. Bahasa
Google juga akan menggolongkan hasil pencarian berdasarkan
bahasa dan negara.
6. Konten Umum
Ini seperti gambar, video, berita, peta, dan lain-lain yang
juga akan diikutsertakan dalam halaman hasil pencarian.
Semua proses di atas berlangsung dalam 1/8 detik sebelum
dikirimkan ke layar user.
Algoritma Search Engine
Search engine menggunakan beberapa macam algoritma
pencarian, yaitu sebagai berikut.
1. List Search
Algoritma ini bekerja dengan cara mencari secara berurutan.
Kita bisa membayangkannya seperti saat kita ingin mencari seseorang dalam
sebuah antrian. Maka kita mencarinya dengan cara memeriksa satu persatu, dari
awal antrian hingga kita menemukan orang yang ingin kita cari. Cara atau algoritma seperti ini biasanya digunakan saat kita
ingin mencari dengan menggunakan satu faktor atau satu kunci saja sebagai
penentu. Untuk antrian yang pendek, cara ini mungkin cukup efektif dan efisien.
Tapi untuk mencari sebuah kata dari milyaran web page yang ada di internet,
maka akan membutuhkan waktu yang sangat lama.
2. Tree Search
Bayangkan sebuah pohon! Bayangkan mulai dari akar, batang,
cabang, kemudian ranting-rantingnya. Begitulah cara kerja dari algoritma ini.
Algoritma ini akan bekerja dengan cara mencarinya dari yang paling mendekati
hingga ke yang paling tidak mendekati. Atau bisa juga dikatakan dari yang
paling umum hingga ke yang paling spesifik, atau sebaliknya. Algoritma ini mirip dengan cara yang digunakan orang untuk
mengatur internet. Seperti yang kita tahu, setiap situs yang ada di internet
itu mempunyai keterkaitan antara satu dengan yang lainnya. Kita bisa menelusuri
keterkaitan ini dengan cara memulai dari tingkat yang paling kecil dulu,
kemudian ke tingkat yang paling besar, atau sebaliknya.
Tree searches adalah cara yang ampuh digunakan untuk
melakukan pencarian di internet, akan tetapi cara ini tidak selalu memberikan
hasil yang memuaskan.
3. SQL Search
Diambil dari kata sequel. Satu kelemahan saat melakukan
pencarian menggunakan metode Tree Search yaitu pencarian dilakukan dengan cara
dari point ke point, atau dari satu titik ke titik. Itu artinya data harus
dicari secara hirarki, dari besar ke kecil atau sebaliknya. Dan kelemahan ini
bisa teratasi dengan menggunakan SQL search.
4. Informed Search
Algoritma informed search bekerja dengan cara mencari solusi
yang spesifik atau khusus dari sebuah dataset yang bercabang-cabang (tree
dataset). Sesuai dengan namanya, algoritma ini tidak selalu cocok digunakan
untuk melakukan pencarian di internet. Karena algoritma ini cuma cocok
digunakan untuk pemecahan masalah-masalah yang spesifik atau khusus saja.
Sedangkan kita seringkali ingin mencari pemecahan untuk masalah-masalah yang
bersifat umum atau luas.
5. Adversarial Search
Adversarial search bekerja dengan cara mencari berbagai
kemungkinan solusi atas sebuah masalah. Ini seperti saat kita melakukan
permainan rolex atau gambling, dimana semua kemungkinan akan kita coba.
Algoritma ini sulit digunakan untuk melakukan pencarian di internet, sebab
berapa banyak kemungkinan yang akan di dapat untuk mencari sebuah kata di
internet? Nyaris tak terhingga.
6. Constraint
Satisfaction Search
Saat kita mencari suatu kata/kalimat di internet, maka
algoritma constraint satisfaction search ini sepertinya adalah metode yang
paling mendekati atau sesuai dengan keinginan mu. Algoritma pencarian jenis
ini, akan mencari solusi dengan cara memberikan berbagai alternatif pilihan.
Algoritma ini akan mencari dengan berbagai cara, dan tidak harus dengan cara
yang berurutan.
Cara Kerja Information
Retrieval
Information Retrieval memiliki cara kerja seperti berikut.
1. Tokenisasi (tokenizing)
atau word token
Tokenisasi (tokenizing) atau word token adlaah pemisahan
deret kata dalam kalimat, paragrap menjadi potongan kata tunggal (termed word)
serta menghilangkan karakter-karakter dalam tanda baca dan mengubah kumpulan
termed menjadi huruf kecil (lower case). Contoh : "saya belajar
Information Retrieval" maka akan dihasilkan : "saya",
"belajar", "information", "retrieval".
2. Stopword removal atau
seleksi / penyaringan (filtration)
Stopword removal atau seleksi / penyaringan (filtration) adalah
tahapan untuk mempersentasikan suatu dokumen dapat mendeskripsikan isi dari
suatu dokumen untuk membedakan isi dokumen lain, dalam suatu istilah (term)
akan mencari jumlah dokumen yang diangap paling relevan didalam suatu inputan
(query), suatu term yang sering ditampilkan atau digunakan diangap sebagai
stopword. Contoh : Operator Logika and, or, not, dan sebaginya. Maka stopword
tersebut akan menghapus, karna frekuwnsi dari kemunculan trem terlalu sering.
3. Pembuatan kata dasar (stemming)
Stemming konversi dari trem ke bentuk akar (root) atau
bentuk umum, biasanya dalam dokumen yang mirip atau sama (sinonim) atau bisa
menemukan kata-kata yang terkait dalam sebuah dokumen. Contoh : kita memasukan
kata "menemukan" maka query akan merekomendasikan,
"memperoleh", "mengetahui", "memiliki",
"mendapatkan" dan setrusnya.
4. Proses pembobotan setiap term dalam dokumen (term weighting)
Term weighting yaitu dalam tahapan pembobotan term skema dalam
pembobotan dipilih berdasarkan pembobotan lokal, global atau kedua-duanya (term
frequency dan global inverse document frequency).
Ada tiga hal yang menjadi dasar cara kerja mesin IR yaitu
Proses Crawling, Proses Indexing dan Proses Surving.
a. Proses Crawling
Crawling adalah suatu pekerjaan yang dilakukan oleh
googlebot (biasa dikenal juga dengan istilah robot, atau spider bisa di sebut
juga crawler) dalam menjelajahi halaman-halaman website untuk di indeks pada
google server.
Googlebot terdiri dari set komputer yang berjumlah besar
yang memang difungsikan untuk meng-crawling website-website. Dalam melakukan
tugasnya, googlebot menggunakan suatu algoritma komputer dalam menentukan situs
apa saja yang akan di crawling, seberapa sering, dan berapa banyak halaman yang
akan di indeks.
Proses crawling dalam suatu website dimulai dari mendata
seluruh url dari website, menelusurinya satu-persatu, kemudian memasukkannya
dalam daftar halaman pada google indeks, sehingga setiap kali ada perubahan pada
website, akan terupdate secara otomatis.
b. Proses Indexing
Indexing adalah proses pengumpulan kata-kata atau kalimat
pada suatu halaman web oleh googlebot yang telah ter-crawling sebelumnya. Dalam
prosesnya, konten inilah yang digunakan oleh google sebagai sumber pencarian
untuk selanjutnya ditampilkan sebagai hasil pencarian berdasarkan kata kunci
(keywords) yang kita cari.
Namun perlu diingat bahwa tidak semua konten dapat diproses
oleh googlebot ini. Umumnya konten tersebut adalah link url, judul, tag, nama
file, tipe file, isi halaman (tidak semua) dan beberapa informasi halaman
lainnya.
c. Proses Surving
Surving adalah suatu proses dalam menampilkan suatu halaman
tertentu merujuk kepada kata kunci yang dimasukkan oleh pengguna. Keterhubungan
antara bagaimana hasil akan ditampilkan dengan kata kunci ditentukan oleh
kurang lebih 200 faktor.
Salah satu faktor penentu yang terkenal yang digunakan untuk
menampilkan hasil pencarian adalah page rank. Dengan page rank, suatu halaman
ditampilkan sesuai dengan urutan dengan cara “halaman yang terbanyak di akses
ditampilkan pertama“.
Ketiga proses tersebut di atas dilakukan dalam waktu yang
sangat cepat dan disajikan kepada pengguna ditambah dengan penjelasan jumlah
penemuan dll.
Referensi
http://superblogpedia.blogspot.com/2014/05/cara-kerja-search-engine-google.html
http://trikmudahseo.blogspot.com/2014/01/cara-kerja-search-engine-google.html
http://suyatmobng.blogspot.com/2013/03/pengertian-cara-kerja-dan-masa-depan.html
Selasa, 10 Maret 2015
Nama/NIM: I Gede Kusuma Ary Jaya/1204505034
Jurusan/Fakultas/Universitas: Teknologi Informasi/Teknik/Universitas Udayana
Mata Kuliah: Sistem Temu Kembali Informasi
Dosen: I Putu Agus Eka Pratama, S.T., M.T.
Jurusan/Fakultas/Universitas: Teknologi Informasi/Teknik/Universitas Udayana
Mata Kuliah: Sistem Temu Kembali Informasi
Dosen: I Putu Agus Eka Pratama, S.T., M.T.
Definisi Model Boolean
Model ini merupakan model IR sederhana yang
berdasarkan atas teori himpunan dan aljabar boolean. Boolean sendiri pertama
kali dikembangkan oleh seroang ilmuan matematika bernama George Boole
(1815-1864). Yang dikemukakan sebagai suatu struktur logika aljabar yang
mencakup operasi Logika AND, OR dan NOR, dan juga teori himpunan untuk operasi
union. Di dalam struktur data,
Boolean merupakan sebuah tipe data yang bernilai “True” atau “False” (benar
atau salah). Sehingga didalam IR logika boolean berartikan bahwa data yang di
crawler sesuai atau tidak antara variable – variablenya.
Dalam pengerjaan operator boolean (AND, NOT, OR) ada
urutan pengerjaannya (Operator precedence). Urutannya
adalah:
-
() berarti prioritas yang berada dalam tanda kurung.
-
NOT
-
AND
-
OR
Contoh: Jika
ada query seperti berikut:
-
(Madding OR crow) AND killed OR slain
-
(Brutus OR Caesar) AND NOT (Antony OR Cleopatra)
Misalkan kita ingin mencari dari cerita-cerita
karangan shakespeare yang mengandung kata Brutus
AND Caesar AND NOT Calpurnia. Salah satu cara adalah: Baca semua teks yang
ada dari awal sampai akhir. Komputer juga bisa disuruh melakukan hal ini
(menggantikan manusia). Proses ini disebut grepping.
Melihat kemajuan komputer jaman sekarang, grepping bisa jadi solusi yang baik. Tapi,
kalau sudah bicara soal ribuan dokumen, kita perlu melakukan sesuatu yang lebih
baik. Karena ada beberapa tuntutan yang harus dipenuhi :
-
Kecepatan dalam pemrosesan dokumen yang jumlahnya sangat banyak.
- Fleksibilitas.
- Perangkingan.
Salah
satu cara pemecahannya adalah dengan membangun index dari dokumen.
Logical
NOT
Dapat
mengecualikan item-item dari seperangkat term penelusuran. Pernyataan formulasi
sederhana: A NOT B.
Contoh:
marketing NOT library. Ini artinya user hanya menginginkan dokumen yang
mengandung unsur marketing yang di dalamnya tidak ada unsur marketing yang di
dalamnya tidak ada unsur perpustakaannya.
Logical
AND
Memperbolehkan
penelusur untuk menggunakan pernyataan query ke dalam dua tau lebih konsep
sehingga hasil penelusuran menjadi lebih terbatas. Pernyataan formulasi
sederhana: A AND B.
Contoh:
untuk menelusur marketing and library, user memformulasikan penyataan
penelusuran dengan : marketing AND library.
Dengan
query tersebut maka kita akan menemukandokumen yang mengandung unsur marketing
danperpustakaan saja, dan tidak untuk mendapatkan dokumenyang hanya mengandung
unsur marketing atau perpustakaan saja.
Logical
OR
Memperbolehkan
penelusur untuk secara spesifik menggunakan alternatif term (atau konsep) yang
mengindikasikan dua konsep sesuai dengan tujuanpenelusuran. Hal ini menjadikan
hasil penelusuran menjadilebih luas, karena adanya alternatif dalam penyataan query.
Formulasi
pernyataan sederhana: A OR B.
Contoh:
marketing OR library. Dengan query tersebut maka kita akan mendapatkandokumen
yang mengandung unsur marketing saja, perpustakaan saja, atau yang mengandung
unsur marketing dan perpustakaan.
Kombinasi
Logical AND, OR, NOT
Dapat
mengkombinasikan satu pernyataan ke dalam penelusuran yang kompleks.
Contoh:
marketing AND library OR information centre NOT profit organization. Artinya user
ingin mendapatkan dokumen yang mengandung untur marketing dan perpustakaan tanpa
unsur pusat informasi dan bukan untuk organisasi non profit.
Kelebihan Model Boolean
1. Mudah untuk diimplementasikan.
2. Konsep yang terstruktur.
3.
Operator Boolean bisa mendekati bahasa alami. Cari dokumen tentang demonstrasi
menentang kenaikan harga minyak tanah.
4. AND dapat menemukan hubungan antara konsep Demonstrasi
mahasiswa.
5. OR dapat menemukan terminologi alternatif Demonstrasi
karyawan.
6. NOT dapat menemukan arti alternatif Demonstrasi
memasak.
7. Query sederhana mudah dimengerti.
Kekurangan Model Boolean
1. Pencocokan yang tepat dapat mengambil dokumen terlalu sedikit atau terlalu
banyak.
2.
Sulit untuk pengindexkan, beberapa dokumen yang lebih penting dari pada yang
lain kadang berada dibawah dokumen yang tidak penting.
3. Sulit untuk menerjemahkan query ke dalam ekspresi Boolean.
4. Semua istilah sama-sama berbobot.
5. Lebih seperti pengambilan data dari pencarian informasi.
6. Bahasa alami sangat kompleks. Contoh Dia melihat seseorang di Pantai dengan
teropong.
7. Sering menghasilkan terlalu banyak dokumen.
- Semua dokumen yang cocok akan muncul.
- Sukar mengurutkan dokumen.
8. Sukar untuk mengekspresikan permintaan pemakai yang kompleks.
9.
Pemakai harus belajar Logic Boolean. (Perbendaraan kata pada indeks harus sama
dengan perbendaraan kata pada query.
Referensi
Nama/NIM: I Gede Kusuma Ary Jaya/1204505034
Jurusan/Fakultas/Universitas: Teknologi Informasi/Teknik/Universitas Udayana
Mata Kuliah: Sistem Temu Kembali Informasi
Dosen: I Putu Agus Eka Pratama, S.T., M.T.
Definisi Search Engine Optimization
Jurusan/Fakultas/Universitas: Teknologi Informasi/Teknik/Universitas Udayana
Mata Kuliah: Sistem Temu Kembali Informasi
Dosen: I Putu Agus Eka Pratama, S.T., M.T.
Definisi Search Engine Optimization
Search Engine Optimization (SEO) merupakan salah
satu metode yang mengatasi masalah yang dijabarkan di atas, Search Engine
Optimazation (SEO) adalah kumpulan teknik atau proses yang di gunakan untuk
menjadikan suatu website menjadi lebih mudah diindeks oleh mesin pencari dengan
melakukan optimasi dan modifikasi pada faktor-faktor yang terdapat di dalam webpage
(on page optimization) dan memanfaatkan faktor-faktor yang tidak ada di dalam
webpage tetapi digunakan mesin pencari dalam melakukan perangkingan pada hasil
pencarian (off page optimization).
Sekilas Sejarah Search Engine
Optimization
Menurut Danny Sullivan, istilah search engine
optimization pertama kali digunakan pada 26 Juli tahun 1997 oleh sebuah pesan
spam yang diposting di Usenet. Pada masa itu algoritma mesin pencari belum
terlalu kompleks sehingga mudah dimanipulasi.
Versi awal algoritma pencarian didasarkan sepenuhnya
pada informasi yang disediakan oleh webmaster melalui meta tag pada kode html
situs web mereka. Meta tag menyediakan informasi tentang konten yang terkandung
pada suatu halaman web dengan serangkaian kata kunci (keyword).
Sebagian webmaster melakukan manipulasi dengan cara
menuliskan kata kunci yang tidak sesuai dengan konten situs yang sesungguhnya,
sehingga mesin pencari salah menempatkan dan memeringkat situs tersebut. Hal
ini menyebabkan hasil pencarian menjadi tidak akurat dan menimbulkan kerugian
baik bagi mesin pencari maupun bagi pengguna internet yang mengharapkan
informasi yang relevan dan berkualitas.
Keuntungan Menerapkan Search Engine
Optimization
1. Mendatangkan Traffic yang Banyak
Situs atau blog berada pada halaman satu Search
Engine pasti akan mendatangkan pengunjung (Traffic) yang sangat besar,
tergantung pada keyword yang user target dan besar kecilnya data hasil
pencarian dari Google Planner.
2. Meningkatkan Penjualan
Jika suatu situs menjual suatu produk atau barang
seperti lazada.co.id yang menjual aneka barang seperti laptop atau lainnya,
maka jika ada orang mencari di google dengan keyword “jual laptop murah”
kemudian situs tersebut ranking 1, maka sudah 95% lazada akan mendapatkan
penjualan dari hasil SEO tersebut.
3. Meningkatkan Daya Saing
Mudah saja untuk keuntungan SEO yang satu ini, jika
posisi suatu situs lebih tinggi maka secara otomatis daya saingnya pun akan
lebih tinggi.
Cara Kerja Search Engine
Mesin pencari web bekerja dengan cara menyimpan hampir
semua informasi halaman web, yang diambil langsung dari www. Halaman-halaman
ini diambil secara otomatis. Isi setiap halaman lalu dianalisis untuk
menentukan cara mengindeksnya (misalnya, kata-kata diambil dari judul,
subjudul, atau field khusus yang disebut meta tag). Data tentang halaman web
disimpan dalam sebuah database indeks untuk digunakan dalam pencarian
selanjutnya. Sebagian mesin pencari, seperti Google, menyimpan seluruh atau
sebagian halaman sumber (yang disebut cache) maupun informasi tentang halaman
web itu sendiri Ketika seorang pengguna mengunjungi mesin pencari dan
memasukkan query, biasanya dengan memasukkan kata kunci, mesin mencari indeks
dan memberikan daftar halaman web yang paling sesuai dengan kriterianya,
biasanya disertai ringkasan singkat mengenai judul dokumen dan terkadang
sebagian teksnya. Mesin pencari lain yang menggunakan proses real-time, seperti
Orase, tidak menggunakan indeks dalam cara kerjanya. Informasi yang diperlukan
mesin tersebut hanya dikumpulkan jika ada pencarian baru.

SEO atau yang biasa disebut search engine
optimization adalah sebuah teknik pemasaran yang sering dilakukan dalam dunia
bisnis internet yang bertujuan untuk mendatangkan banyak pengunjung secara
tertarget melalui mesin pencari seperti Google, Yahoo, Bing, dll. Keyword
merupakan hal yang vital dalam SEO. Kesalahan dalam menentukan keyword dapat
berakibat pengunjung tidak melimpah, dan sebaliknya, jika tepat menentukan
keyword dalam SEO akan berdampak signifikan dalam menghasilkan ribuan pengunjung
setiap harinya. Strategi untuk menentukan keyword dalam SEO menjadi hal yang
harus diperhitungkan dalam pesaingan di dunia SEO. Keyword yang berkaitan merupakan
keyword yang memiliki makna hampir sama dengan keyword utama. Untuk melakukan
pencarian sinonim, penulis menggunakan berbagai tool, antara lain dari gorank.com
atau menggunakan kamus dan software translator lainnya.
Dengan melakukan serangkaian teknik optimasi
tersebut diharapkan suatu website bisa menduduki posisi terbaik di hasil pencarian.
Ada pun posisi terbaik adalah posisi yang mudah ditemukan orang dalam suatu
kalimat pencarian. Biasanya posisi yang sering dikunjungi orang adalah antara halaman
1 (lebih dominan) sampai halaman 3. Jika sampai halaman tersebut pengunjung
belum mendapat informasi yang dibutuhkannya, maka ia akan beralih menggunakan
kalimat pencarian lainnya. Untuk itulah bisa berada di posisi tersebut
merupakan suatu target jika menggunakan teknik SEO ini. Terlebih bisa berada di
Page 1 apalagi sampai peringkat 3 besar, pasti akan mendapatkan banyak
kunjungan dari mesin pencari.
Software yang dapat digunakan dalam
Search Engine Optimization
1. Adobe Dreamweaver CS3
Adobe Dreamweaver CS3 adalah software yang berguna
untuk mendesain web visual yang mempunyai keunggulan WYSIWYG (What You See Is
What You Get) ini tidak harus berurusan dengan tag-tag HTML untuk membuat
sebuah web. Dreamweaver tidak hanya digunakan untuk menuliskan text-text HTML,
namun juga dapat mendesain halaman web yang interaktif. Adobe Dreamweaver CS3
juga mendukung berbagai bahasa pemprograman web seperti PHP.
2. Web Browser
Web browser adalah sebuah aplikasi yang berguna
untuk menjelajahi internet, menampilkan informasi dari suatu alamat situs web,
baik itu tulisan, gambar bahkan saat ini teknologi web browser yang sudah diperbaharui
mampu untuk menampilkan animasi, video klip hingga film berdurasi panjang.
Unsur Pendukung Penerapan SEO
1. On Page SEO
On Page SEO adalah suatu teknik mengoptimisasi
halaman website dengan menerapkan beberapa dasar keyword yang ditarget
kedalamnya. Keuntungan dari on page seo ini yaitu situs anda akan lebih dinilai
relevan oleh google, juga jika halaman tersebut hanya mendapatkan sedikit
backlink bisa dipastikan akan mudah ranking #1 Google. Dasar yang harus
diterapkan dalam On Page SEOadalah:
a. Title Tag
Title Tag mirip seperti judul pada
suatu posting/artikel tetapi berbeda, karena umumnya title tag ini dibaca oleh
search engine, jika title tag tidak diganti atau sama menyerupai judul posting
maka yang muncul pada search engine sebagai title tag yaitu judul posting
tersebut. Berikut gambar contoh title tag.

b. Meta
Description
Meta descriptions adalah keterangan dari suatu
halaman berdasarkan dari kalimat artikel postingan, agar meta description
terlihat menggoda dan menarik trafik, perlu memodifikasinya dengan menggunakan
plugin SEO. Berikut gambar contoh Meta Description.

c. URL
URL singkatan dari Uniform Resource
Locator, adalah rangkaian karakter menurut suatu format standar tertentu, yang
digunakan untuk menunjukkan alamat suatu sumber seperti dokumen dan gambar di
Internet.
d. Heading
Heading adalah sekumpulan kata yang menjadi judul atau
sub-judul dalam sebuah dokumen html.
e. Link to
Authority Site
Link to Authority Site merupakan
sebuah posting yang di dalamnya terdapat link menuju situs–situs terpercaya/yang
dipercayai google seperti yotube, wikipedia, facebook, dan lain-lain.
2. SEO OFF PAGE
Off-page SEO adalah aktifitas atau teknik SEO yang
dilakukan diluar blog atau website tersebut. Banyak hal yang bisa dilakukan
dalam off-page SEO ini, antara lain :
a. Exchange Link atau Bertukar Link dengan
blog lain.
b. Mensubmit blog ke search engine .
c. Mendaftarkan blog ke Web atau blog
directory misal DMOZ.org.
d. Mendaftarkan
blog ke social bookmark misal Technorati, digg, Del.cio.us dll.
e. Mendaftarkan
blog atau website ke social media misal myblog atau blogcatalog.
f. Memasang
iklan di iklan baris.
g. Memasang
iklan pada blog atau web yang bertrafik tinggi dan ber PR (Page Rank) tinggi.
h. Mensubmit
pillar artickel ke beberapa article directory.
i. Bergabung
ke beberapa forum diskusi.
Komponen-komponen Diagram
SEO


Komponen komponen SEO mulai dari On page untuk
Keyword Research (analisa keyword) fungsi analisa keyword adalah untuk
memenangkan kompetisi keyword yang banyak dicari dan untuk mentargetkan keyword
untuk visitor, menambah kekuatan dari on page diberi backlink anchor text untuk
lebih memperkuat keyword target dari jumlah backlink yang berkualitas, untuk
mencapai keyword yang tertujuh dan membuat website yang kualitasnya yang sangat
baik, yang bisa disukai user betah lama-lama di website tersebut.
Contoh Implementasi Mengoptimasi Website di Situs Pencarian Google dan Yahoo
Proses implementasi yang dilakukan dalam
mengoptimasi website di situs pencarian Google dan Yahoo yaitu :
1. Dengan
cara mendaftarkan situs website terlebih dahulu ke situs pencarian google dan
Yahoo atau Langsung ke website submit URL Web ke beberapa search engines http://www.submitexpress.com/free-submission.html
Kemudian
setelah didaftarkan ke layanan submit search engine maka langkah selanjutnya
mendaftarkannya di Google webmaster. Sesudah mendaftar dan memasukkan
website/blog tersebut kemudian submit sitemap untuk website dengan format XML,
bila menggunakan platform CMS wordpress bisa menggunakan Plugins Google Sitemap
XML bisa didownload melalui (http://wordpress.org/extend/plugins/google-sitemap-generator/).
2. Proses
yang kedua adalah mengoptimasi website tersebut dengan cara pengujian yang
telah disebutkan di bab ke-tiga yaitu SEO basic. Dengan memperbaiki meta
tag,membuat beberapa keyword atau kata kunci,struktur website dan lain
sebagainya.
3. Proses
yang ketiga adalah dengan mendaftarkan website ke situs statstik visitor untuk
mengetahui statistic atau dapat dijadikan data untuk melihat pengunjung website
dari Negara mana saja,berapa jumlah pengunjung dan presentase kunjungan
perhari, disini penulis memakai webmaster tools yaitu histats.com dan extremetracking.com.
4. Proses
keempat adalah memonitoring website setiap hari, berguna untuk melihat data
berada pada posisi berapa dan di halaman ke berapa di situs pencarian atau sama
sekali tidak ada.
Referensi
ANALISA DAN
IMPLEMENTASI SEO (Search Engine Optimization) KONTEN WEBSITE UNTUK
ALGORITMA GOOGLE PANDA DAN YAHOO oleh Firman Dwi Prasetyo JURUSAN TEKNIK
INFORMATIKA SEKOLAH TINGGI MANAJEMEN INFORMATIKA DAN KOMPUTER AMIKOM, YOGYAKARTA
Selasa, 03 Maret 2015
Nama/NIM: I Gede Kusuma Ary Jaya/1204505034
Jurusan/Fakultas/Universitas: Teknologi Informasi/Teknik/Universitas Udayana
Mata Kuliah: Sistem Temu Kembali Informasi
Dosen: I Putu Agus Eka Pratama, S.T., M.T.

Jurusan/Fakultas/Universitas: Teknologi Informasi/Teknik/Universitas Udayana
Mata Kuliah: Sistem Temu Kembali Informasi
Dosen: I Putu Agus Eka Pratama, S.T., M.T.
Definisi Information Retrieval
Information
Retrieval (IR) adalah bagaimana menemukan suatu dokumen dari
dokumen-dokumen tidak terstruktur yang memberikan informasi yang dibutuhkan
dari koleksi dokumen yang sangat besar yang tersimpan dalam komputer. (Manning,
2008). ISO 2382/1 mendefinisikan IR sebagai tindakan, metode dan prosedur demi menemukan
kembali data yang tersimpan untuk menyediakan informasi mengenai subyek yang
dibutuhkan. Tidakan tersebut mencakup text indexing, inquiry analysis, dan
relevance analysis; data mencakup text, tabel, gambar, ucapan, dan video;
sedangkan informasi termasuk pengetahuan relevan yang dibutuhkan untuk mendukung
penyelesaian masalah dan akuisisi pengetahuan.
Tujuan dari sistem IR
adalah untuk memenuhi kebutuhan informasi pengguna dengan meretrieve semua
dokumen yang mungkin relevan, pada waktu yang sama me-retrieve sesedikit
mungkin dokumen yang tidak relevan. Sistem IR yang baik memungkinkan pengguna
menentukan secara cepat dan akurat apakah isi dari dokumen yang diterima
memenuhi kebutuhannya. Tujuan yang harus dipenuhi adalah bagaimana menyusun
dokumen yang telah didapatkan tersebut ditampilkan terurut dari dukumen yang
memiliki tingkat relevansi tinggi ke tingkat relevansi yang lebih rendah.
Penyusunan dokumen tersebut disebut sebagai perangkingan dokumen.
Model IR adalah model
yang digunakan untuk melakukan pencocokan antara termterm (kata) dari query
dengan term-term dalam document collection (folder file), model yang terdapat
dalam IR terbagi dalam 3 model besar, yaitu :
a. Set-theoritic models
Model ini merepresentasikan
dokumen sebagai himpunan kata atau frase. Contoh model ini adalah Standard Boolean model dan Extended Boolean model.
b. Algebraic model
Model merepresentasikan
dokumen dan query sebagai vektor similarity antara vektor dokumen dan vektor query yang direpresentasikan sebagai
sebuah nilai skalar. Contoh model ini adalah Vektor Space Model (model ruang vektor), Latent Semantic Indexing (LSI) dan Generalized Vector Space Model (GVSM).
c. Probabilistic model
Model ini memperlakukan
proses pengambilan dokumen sebagai sebuah probabilistic
inference. Contoh model ini ialah penerapan teorema bayes dalam model probabilistik.
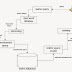
Proses Searching Information Retrieval
Ilustrasi
mengenai bagaimana proses searching
information retrieval dapat dilihat pada Gambar 1.
Gambar 1. Proses Searching
Beberapa proses yang
terjadi saat melakukan search sesuai dengan ilustrasi Gambar 1 yaitu :
a. Parse query yaitu memecah query menjadi
bentuk token.
b. Proses Stopword filtration.
Token-token
query yang telah dihasilkan pada
proses parse query kemudian difilter melalui proses pembuangan token
yang termasuk Stopword.
c. Proses Stemming
Stopword
tokens dari proses stopword sebelumnya kemudian difilter kembali melalui proses stemming sehingga menghasilkan stemmed term query.
d. Transformasi Query
Stemmed
term query yang dihasilkan kemudian ditransformasikan apabila
memerlukan. Artinya, apabila query
yang diinputkan membutuhkan terjemahan ke dalam bentuk query bahasa lain maka sebelum mencari dokumen pada koleksi
dokumen, query tersebut diterjemahkan
duhulu melalui proses penerjemahan query.
Sistem akan membandingkan query
tersebut dengan koleksi dokumen sehingga mengembalikan dokumen-dokumen yang
relevan dalam suatu bahasa yang berbeda dengan bahasa query.
e. Pemodelan dalam model ruang vektor
Tiap term atau kata yang ditemukan pada
dokumen dan query diberi bobot dan
disimpan sebagai salah satu elemen vektor dan dihitung nilai kemiripan antara query dan dokumen.
f. Perangkingan
dokumen atau konten berdasarkan nilai kemiripan antara query dan dokumen.
Peranan Information Retrieval
Information
Retrieval memiliki beberapa peranan yang sangat penting bagi
penggunanya antara lain:
a. Menganalisis
isi sumber informasi (dokumen).
b. Mengidentifikasi
sumber informasi yang relevan dengan minat masyarakat pengguna yang ditargetkan.
c. Menyempurnakan
unjuk kerja sistem berdasarkan umpan balik yang diberikan oleh pengguna.
d. Menemu-kembalikan
informasi yang relevan.
e. Mempertemukan
pernyataan pencarian dengan data yang tersimpan dalam basis data.
f. Merepresentasikan
pertanyaan (query) pengguna dengan cara tertentu yang memungkinkan untuk
dipertemukan sumber informasi yang terdapat dalam basis data.
g. Merepresentasikan
isi sumber informasi dengan cara tertentu yang memungkinkan untuk dipertemukan
dengan pertanyaan (query) pengguna.
Contoh Information Retrieval
User menggunakan search engine Google dalam melakukan searching informasi tentang tim robot kampus Universitas Udayana,
di mana:
a. Dibiayai
oleh PENS-UNUD.
b. Ikut
serta dalam turnamen internasional kontes robot di Jepang.
User
melakukan search dengan keyword “tim robot UNUD yang dibiayai
PENS-UNUD dan pernah ikut turnamen internasional di Jepang”.
Deskripsi
kebutuhan informasi user demikian
tidak dapat langsung didapatkan meski melalui search engine Google. Sebaliknya, user harus menterjemahkan terlebih dahulu kebutuhan informasi yang
diharapkan melalui suatu query yang
kemudian akan diproses oleh search engine.
Hasil dari penerjemahan oleh user
tadi berupa keyword (index) atau kata kunci yang merupakan
ringkasan dari deskripsi tadi. Sehingga dari keyword yang dimasukkan user
untuk pencarian tadi, sistem IR akan mencari informasi, yang mana informasi
yang didapatkan mengandung relevansi/keterkaitan dengan yang diharapkan user tadi misalkan “turnamen International robot PENS-UNUD” atau “tim
robot PENS-UNUD”.
Referensi
IMPLEMENTASI
METODE GENERALIZED VECTOR SPACE MODEL PADA APLIKASI INFORMATION RETRIEVAL oleh Jasman Pardede, Mira Musrini Barmawi, Wildan
Denny Pramono
Langganan:
Komentar (Atom)